






TECH ARTICLES
LSCM has been working closely with different sectors to drive the development of innovative technologies to assist the industry in enhancing operational efficiency and productivity. The Centre is also committed to facilitating knowledge exchange and sharing. This webpage gathers the most recent updates and trends of technology development and expert insights provided by industry leaders and the academia, enabling the industry practitioners to obtain the latest industry news and updates.

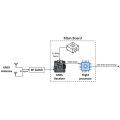


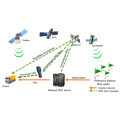
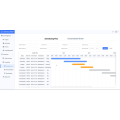



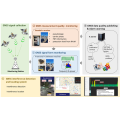
All information on this “Tech Articles” webpage (including but not limited to information, content, views, or images) is provided by the authors and does not represent the views and / or position of LSCM. While LSCM endeavours to ensure that the information of this webpage is accurate and complete, it shall not be held responsible for any errors or omissions.